
I’ve been waiting for this feature for what feels like forever.
Databricks-Connect is here! You can download here. It allows you to develop using an IDE like VSCode, PyCharm, IntelliJ etc and connect to a remote Databricks cluster to execute the task.
This means we can bring much better development experiences and best practices to data engineering workloads. Notebooks are great for exploring data, but they are not enterprise code for ETL jobs. They are near impossible to test, have zero concept of classes and methods which developers expect, and they are really designed for interactive use - not batch processing.
Previously you could create a PySpark application and execute it as a job. But this was very clunky - and you missed all the good features of Databricks like Delta, DBUtils etc.
Setup is pretty straightforward. The link above has detailed instructions, but in short I’ve summarised below.
Windows Users
UPDATE April 2019 - I recommend Windows users read through this blog post before continuing. Mac/Linux users - as you were.
UPDATE June 2020 - How about using a container? It’s much easier than installing all this stuff: Prebuilt container
Cluster Setup
First you need to enable the feature on your Databricks cluster. Your cluster must be using Databricks Runtime 5.1 or higher. In the web UI edit your cluster and add this/these lines to the spark.conf:
spark.databricks.service.server.enabled true
If you are using Azure Databricks also add this line:
spark.databricks.service.port 8787
(Note the single space between the setting name and value).
Restart your cluster.
Virtual Environment
Create a new Virtual environment, ensuring that Python matches your cluster (2.7 or 3.5). If you are using Anaconda then this command will create it for you:
conda create --name dbconnect python=3.5
Switch to the environment:
conda activate dbconnect
If you are re-using an existing environment uninstall PySpark before continuing. Now install the Databricks-Connect library:
pip install -U databricks-connect==5.1.* # or 5.2.*, etc. to match your cluster version
Configure Library
At prompt run:
databricks-connect configure
Complete the questions - they are pretty straightforward. Once done you can run this command to test:
databricks-connect test
If you get any errors check the troubleshooting section. But hopefully you are good to go.
VSCode
I’m going to use VSCode because it’s my tool of choice. You should install the Python extension first (if you haven’t got it already). Also consider disabling linting because you will get lots of red squiggles.
Create a new py file in any folder and paste in this code:
from pyspark.sql import SparkSession
from pyspark.sql.functions import lit, col
spark = SparkSession.builder.getOrCreate()
# Extract
df = spark.read.format("csv").option("header", "true").load("/databricks-datasets/asa/planes")
# Transform
df = df.withColumn("NewCol", lit(0)).filter(col("model").isNotNull())
# Load
df.write.format("delta").mode("overwrite").saveAsTable("planes")
# Verify
resDf = spark.sql("SELECT * FROM planes")
resDf.show()
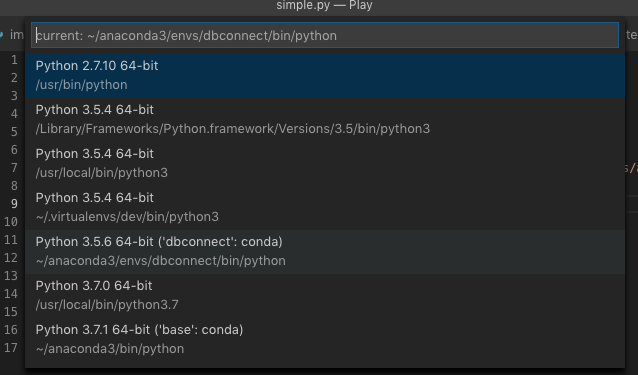
You now need to ensure you have the right interpreter. From the Command Palette type: “select interpreter” and press enter:

Select your virtual environment that you created above:
You will only have to do that once. You can now execute your code by pressing F5, hopefully you will see this:
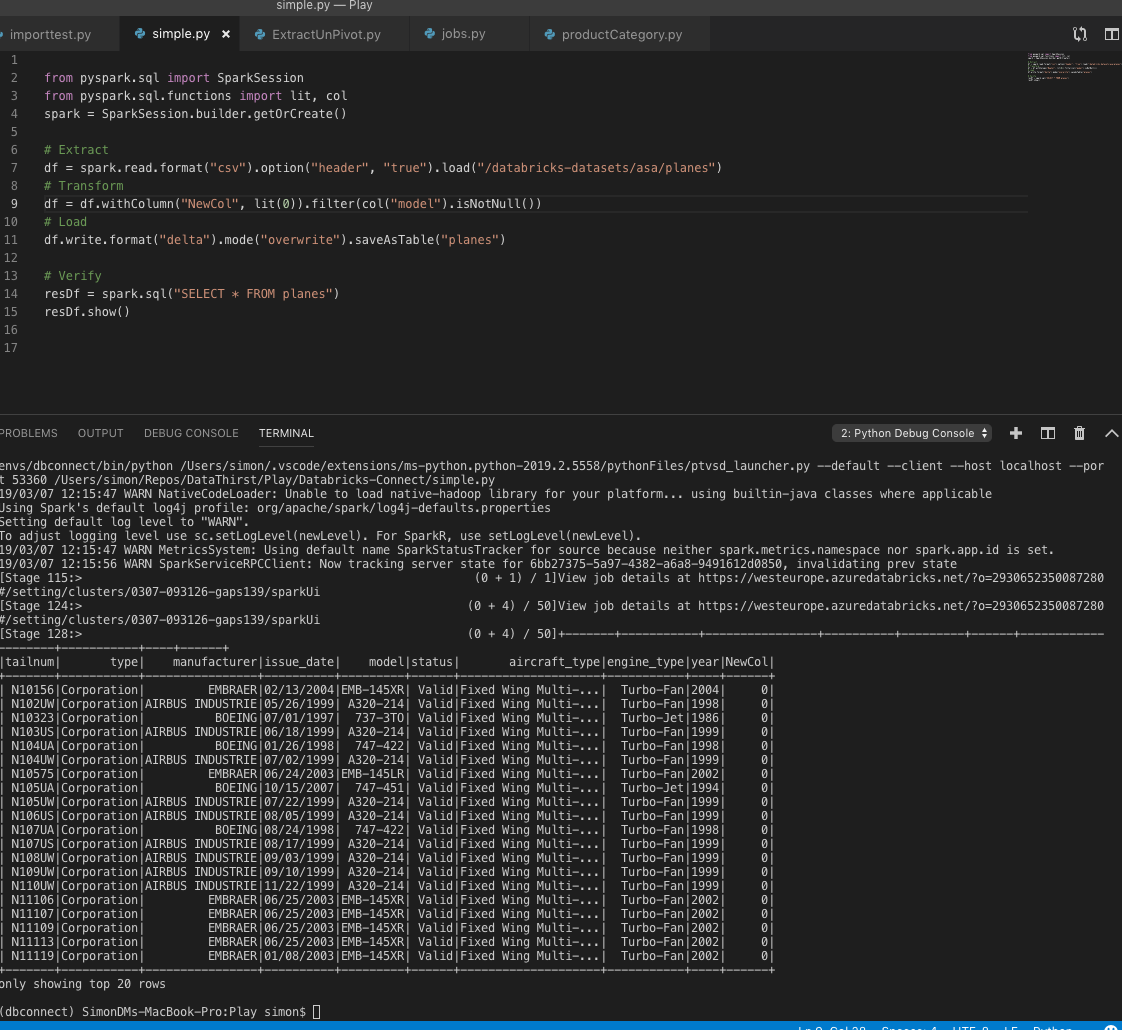
Debugging
Now for the heavenly bit. You can now debug by adding breakpoints to your code. Simply add a breakpoint, then you can hover over variables to view them etc! No more debugging 1980’s style with Print statements everywhere.
You can also use the Peak Definition and Go To Definition options in VSCode:
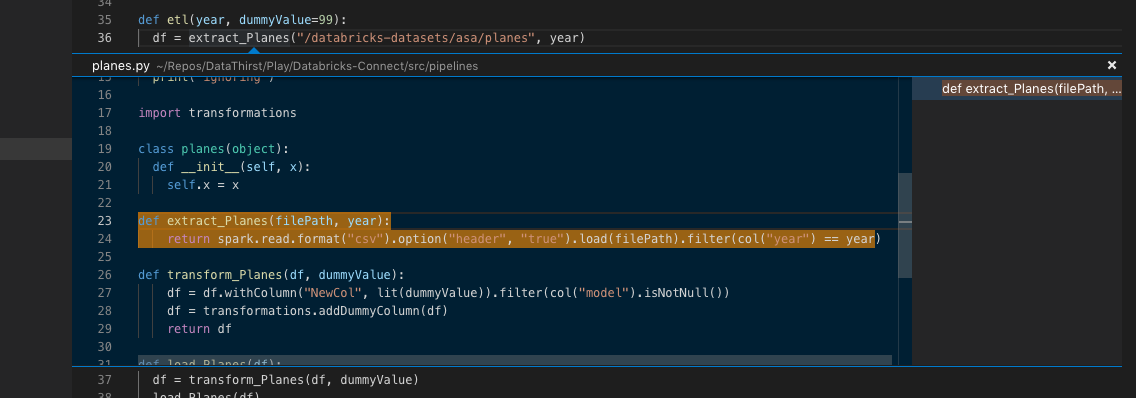
Thats awesome!!!!!
Notes
A few notes: in you Python files you will need to add these lines at the start of PySpark modules (normally notebooks do this for you in the background):
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
If you want to use DBUtils you will need to run this first:
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark.sparkContext)
Note that DBUtils will work locally but will not work if you deploy your code to your cluster and execute server side - this is a known issue.
There are some limitations with Databricks-Connect you should be aware of before getting too far in.
Wrap Up
I think that this is a huge step forward for data engineering in Databricks. I will post some more blogs around best practices and getting this working with CI/CD tools.