Problem
I recently encountered a file similar to this:
The data required “unpivoting” so that the measures became just three columns for Volume, Retail & Actual - and then we add 3 rows for each row as Years 16, 17 & 18.
Their are various ways of doing this in Spark, using Stack is an interesting one. But I find this complex and hard to read.
First lets setup our environment and create a function to extract our sample data:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, array, explode, lit
from pyspark.sql.types import StringType, IntegerType, StructField, StructType
spark = SparkSession.builder.appName("TestUnpivot").getOrCreate()
def extract():
customSchema = StructType([ \
StructField("id", IntegerType(), True), \
StructField("txt", StringType(), True), \
StructField("name", StringType(), True), \
StructField("Volume16", IntegerType(), True), \
StructField("Volume17", IntegerType(), True), \
StructField("Volume18", IntegerType(), True), \
StructField("Retail16", IntegerType(), True), \
StructField("Retail17", IntegerType(), True), \
StructField("Retail18", IntegerType(), True), \
StructField("Actual16", IntegerType(), True), \
StructField("Actual17", IntegerType(), True), \
StructField("Actual18", IntegerType(), True)
])
return spark.read.format('csv').options(header='true', inferSchema=False, mode="DROPMALFORMED").load('sourcefile.csv', schema=customSchema)
Now lets look at simple & readable way to turn this is into rows from the given columns using UnionAll to concatenate 3 dataframes together (one for each year).
def transform(df):
df16 = df.select("id","txt","name",lit(16).alias("year"),col("Volume16").alias("Volume"), col("Retail16").alias("Retail"), col("Actual16").alias("Actual"))
df17 = df.select("id","txt","name",lit(17).alias("year"),"Volume17", "Retail17", "Actual17")
df18 = df.select("id","txt","name",lit(18).alias("year"),"Volume18", "Retail18", "Actual18")
transformedDf = df16.unionAll(df17).unionAll(df18)
return transformedDf
By creating the 3 dataframes and using lit to create our Year column we can Unpivot the data. The code above would not be good if we had an unknown number of Years. For that scenario you would need to write a loop, and probably guess the number of times to iterate on based on the number of columns in the source dataframe.
Finally execut
df = extract()
df = transform(df)
df.show()
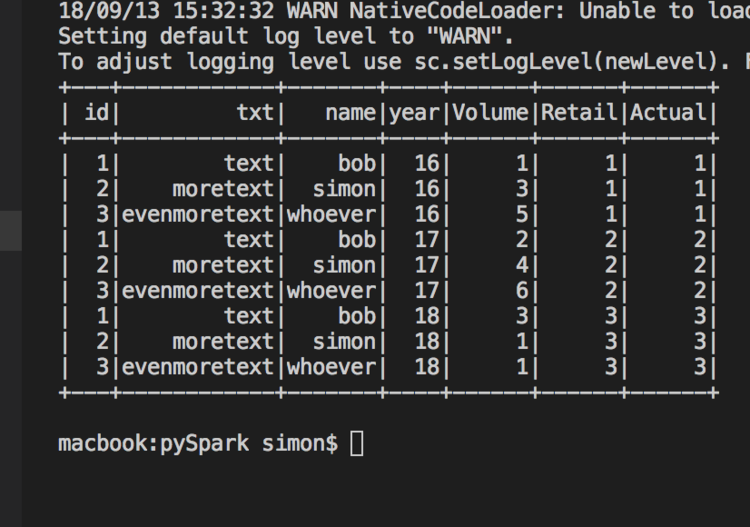
And the final results using df.show():